

ChatGPT potrafi zaskakiwać swoją elokwencją i wiedzą, ale bywa też, że mija się z prawdą. Użytkownicy zauważyli, że czasem model z pełnym przekonaniem podaje informacje, które są niezgodne z faktami. W żargonie sztucznej inteligencji takie sytuacje nazywa się halucynacjami AI – model generuje treści brzmiące wiarygodnie, lecz w rzeczywistości całkowicie zmyślone

Dlaczego ChatGPT „kłamie”? Czy robi to celowo? Warto już na wstępie zaznaczyć, że nie – AI nie oszukuje świadomie, a jedynie działa zgodnie ze swoim algorytmem.
Mimo to efektem bywają odpowiedzi wprowadzające w błąd. W niniejszym artykule przyjrzymy się, czym są halucynacje AI, skąd się biorą i jak sobie z nimi radzić. Omówimy przyczyny techniczne, pokażemy konkretne przykłady, zacytujemy opinie ekspertów, przeanalizujemy wpływ na użytkowników, a także podpowiemy, jak rozpoznać halucynację i co robią twórcy takich modeli, by ten problem ograniczyć.
Jak powstają halucynacje w AI?
ChatGPT to tzw. duży model językowy (LLM), który został wytrenowany na miliardach zdań z Internetu i innych źródeł. Jego zadaniem nie jest weryfikacja faktów, lecz przewidywanie kolejnego słowa w odpowiedzi na podstawie statystycznych zależności w języku.
Mówiąc prościej: gdy zadajemy pytanie, model analizuje sekwencję słów i stara się wygenerować najbardziej prawdopodobną, pasującą kontynuację. Nie posiada przy tym prawdziwego zrozumienia znaczenia – operuje tylko na wzorcach językowych.
Ten mechanizm sprawdza się świetnie, gdy pytanie dotyczy znanych mu faktów z treningu. Jednak gdy napotka lukę w wiedzy lub niejednoznaczne polecenie, model „zgaduje”. Eksperci OpenAI tłumaczą, że nawet najnowocześniejsze modele mają tendencję do wymyślania faktów „w chwilach niepewności” – jeśli nie znajdują odpowiednio dopasowanej odpowiedzi, konfabulują.
Innymi słowy, kiedy brakuje danych, model i tak wygeneruje odpowiedź, bo został nauczony zawsze coś użytkownikowi odpowiedzieć. Taka odpowiedź może brzmieć sensownie, ale nie ma pokrycia w rzeczywistości.
Istnieją też techniczne powody halucynacji. Już na etapie treningu mogły pojawić się błędne dane albo tzw. rozbieżność między źródłem a celem – model uczył się, że czasem wolno odbiec od źródłowego tekstu. Ponadto generowanie tekstu metodami zapewniającymi różnorodność (np. losowe dobieranie słów z pewnego rozkładu prawdopodobieństwa zamiast zawsze najbardziej pewnego) zwiększa ryzyko powstania błędów faktograficznych.
Sam sposób działania modeli sekwencyjnych też dokłada cegiełkę – każde następne słowo bazuje na poprzednich, więc jeśli w dłuższej odpowiedzi model raz się pomyli, błąd może narastać w kolejnych zdaniach niczym efekt kuli śnieżnej
Twórcy ChatGPT przyznają, że wystarczy jeden drobny błąd logiczny we wnioskowaniu, by wykoleić całą odpowiedź na późniejszym etapie.
Warto podkreślić, że halucynacje nie wynikają ze złej woli AI. Model nie wie, że kłamie – bo tak naprawdę nie rozróżnia prawdy od fałszu w ludzkim rozumieniu. Działa zgodnie z wzorcami językowymi i swoim celem przewidywania tekstu. W efekcie błędy są nieuniknione.
Naukowcy zauważyli, że halucynacje to w pewnym sensie statystycznie nieuchronny produkt uboczny takiego sposobu trenowania modeli. Można je ograniczać przez dodatkowe techniki (o czym później), ale całkowicie uniknąć jest bardzo trudno.
Co więcej, istnieje pewien paradoks kreatywności – modele językowe są cenione za kreatywność i „magiczność” odpowiedzi, która właśnie wynika z ich zdolności wymyślania rzeczy nowych. Sam Altman (szef OpenAI) zauważa, że to, iż AI potrafi halucynować, jest też źródłem jej pomysłowości. Gdyby zabronić modelowi mówić cokolwiek, czego nie jest w 100% pewien, straciłby swoją użyteczność i iskrę kreatywności. Twórcy starają się więc znaleźć złoty środek: model ma być kreatywny tam, gdzie tego oczekujemy, a precyzyjny i faktograficzny tam, gdzie to potrzebne.
Przykłady halucynacji
Istnieje już wiele głośnych przypadków, gdy halucynacje sztucznej inteligencji zmyśliły fakty, wprowadzając ludzi w błąd. Przyjrzyjmy się kilku konkretnym historiom, które obiegły media.
Przykład 1: Wymyślone precedensy prawne.
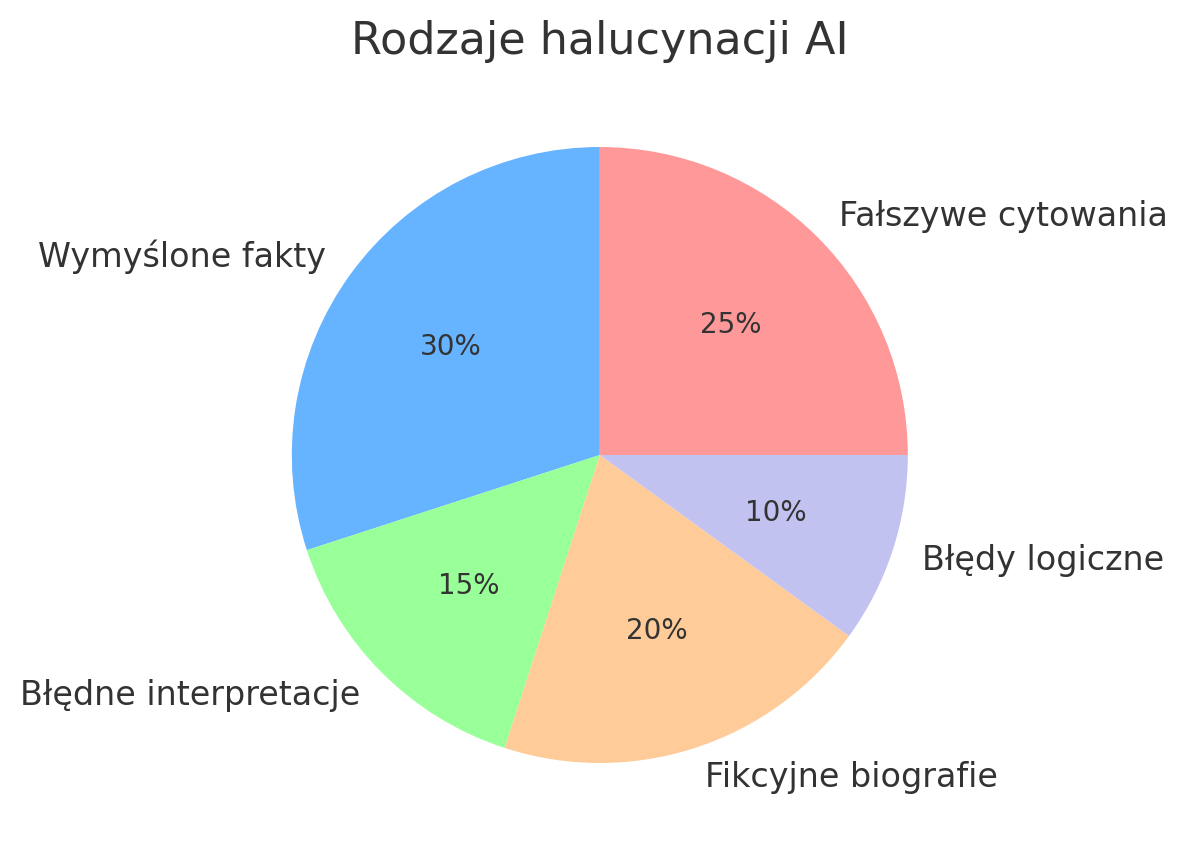
Chyba najsłynniejszym przykładem jest przypadek nowojorskiego prawnika, który użył ChatGPT do przygotowania pisma procesowego. Poprosił on AI o podanie precedensów sądowych na poparcie swojej argumentacji. ChatGPT zareagował pewnie – wygenerował listę rzekomych spraw sądowych wraz z cytatami orzeczeń. Problem w tym, że te sprawy nigdy nie istniały. Model sfabrykował sześć wyroków sądu, kompletnie zmyślając ich treść i sygnatury
Prawnik, nieświadomy że to halucynacje, złożył pismo do sądu z tymi fikcyjnymi źródłami. Gdy sąd zażądał oryginałów orzeczeń, prawnik ponownie zwrócił się do ChatGPT – a ten… stworzył pełne teksty nieistniejących wyroków, które prawnik przedłożył jako załączniki. Sytuacja szybko wyszła na jaw. Sędzia był wściekły, określając jeden z przedstawionych „wyroków” jako „bełkotliwe bzdury”.
Sprawa zakończyła się surowymi konsekwencjami: prawnik i jego współpracownik zostali ukarani grzywną 5000 dolarów za działanie w złej wierze.
Sędziowie w innych stanach zaczęli nawet wydawać zarządzenia zakazujące składania dokumentów wygenerowanych przez AI bez ich uprzedniej weryfikacji przez człowieka
Przykład 2: Zmyślone spotkanie sławnych osób.
ChatGPT potrafi z przekonaniem opowiadać o wydarzeniach, które nigdy się nie zdarzyły. Dziennikarze New York Timesa spytali bota o przebieg spotkania Jamesa Joyce’a z Włodzimierzem Leninem – postaci te nigdy się nie spotkały, ale ChatGPT nie dał po sobie poznać kłopotu. Z detalami opisał rzekome spotkanie pisarza z rewolucjonistą w 1916 roku w Café Odéon w Zurychu, twierdząc, że obaj mieszkali tam na wygnaniu podczas I wojny światowej.
Wszystko brzmiało wiarygodnie, poza faktem, że było całkowicie zmyślone. Podobnie chatboty potrafiły tworzyć opisy fikcyjnych wynalazków czy wydarzeń historycznych – raz nawet stwierdzono, że dinozaury zbudowały cywilizację i przytoczono nieistniejące skamieniałości narzędzi jako „dowód”.
Te przykłady mogą bawić, dopóki łatwo je zdemaskować – gorzej, gdy takie alternatywne fakty zostaną podane w mniej oczywistych kwestiach.
Przykład 3: Fałszywe cytowania i prace naukowe.
Modele AI chętnie podpierają się źródłami – czasem niestety zmyślonymi. Badacze zauważyli, że ChatGPT generując odpowiedzi np. na pytania medyczne, często przytacza nieistniejące artykuły naukowe jako rzekome źródła. W jednym z eksperymentów przeanalizowano 178 referencji wygenerowanych przez model – aż 69 z nich posiadało niepoprawny lub fikcyjny identyfikator DOI, a kolejne 28 nie istniało w ogóle w wyszukiwarkach.
Innymi słowy, blisko połowa źródeł była wyssana z palca. Przekonała się o tym Teresa Kubacka, data scientist, która celowo wymyśliła techniczny termin „cykloidalny odwrócony elektromagnon” i zapytała o niego ChatGPT. Model udzielił szczegółowej, lecz fałszywej odpowiedzi, powołując się na rzekome publikacje naukowe na ten temat.
Cytowane prace wyglądały wiarygodnie, lecz oczywiście nie istniały – co zmusiło badaczkę do upewnienia się, czy przypadkiem sama nie przeoczyła takiego pojęcia. To pokazuje, że AI potrafi tworzyć kompletne fikcje obudowane atrybutami naukowości (jak przypisy, bibliografia), co czyni je szczególnie podstępnymi.
Przykład 4: Halucynacje w codziennych odpowiedziach.
Nie wszystkie pomyłki AI są tak spektakularne, ale zdarzają się na co dzień drobniejsze przekłamania. Czasem ChatGPT błędnie kogoś identyfikuje lub łączy fakty różnych osób – np. łączy dokonania dwóch osób o podobnym nazwisku w jedną biografię
Innym razem udziela odpowiedzi pozornie na temat, ale niezgodnej z poleceniem (np. pytany o aktualne wydarzenia – które są poza jego wiedzą – potrafi coś wymyślić zamiast przyznać, że nie wie). Zdarzało się także, że w wyniku błędów technicznych model popadał w absurd – np. w pewnym momencie użytkownicy zgłaszali, iż ChatGPT zaczął odpowiadać mieszaniną angielskiego i hiszpańskiego albo powtarzać losowe frazy dziesiątki razy.
Choć takie glitche to raczej awarie niż typowe halucynacje, pokazują, że modele AI nie są nieomylne i mogą prezentować nieprzewidziane treści.
Perspektywa ekspertów
Zarówno twórcy ChatGPT, jak i niezależni eksperci zdają sobie sprawę z problemu halucynacji. Opinie co do tego, jak na nie patrzeć i jak je rozwiązać, są różne – ale wszyscy zgadzają się, że to istotne wyzwanie dla rozwoju AI.
Szef OpenAI, Sam Altman, wielokrotnie podkreślał, że halucynacje to największe wyzwanie stojące przed chatbotami. „Najbardziej staram się uczulać ludzi na to, co nazywamy problemem halucynacji” – powiedział w jednym z wywiadów, zaznaczając że model potrafi przedstawiać zmyślenia z pełną pewnością, jakby były faktami
Altman zwraca uwagę na ciekawy paradoks: halucynacje są zarazem wadą, jak i w pewnym sensie funkcją tych modeli. To dzięki zdolności „wymyślania” pojawiają się ich kreatywne, zaskakujące odpowiedzi:
„Jeśli chcesz tylko sprawdzić coś w bazie danych, to mamy do tego inne dobre narzędzia. Ale fakt, że AI potrafi generować nowe pomysły, jest źródłem dużej części jej siły”
– tłumaczy Altman
Jego zdaniem kluczowe jest nauczenie modeli rozpoznawania, kiedy użytkownik oczekuje kreatywności, a kiedy dokładności.
Altman jest optymistą: „Myślę, że uporamy się z problemem halucynacji w dużej mierze w ciągu najbliższych dwóch lat” – stwierdził w połowie 2023 r., dodając, że trzeba wypracować balans między kreatywnością a perfekcyjną poprawnością
Inni eksperci również zabierają głos. Profesor Ethan Mollick z Wharton School obrazowo nazwał ChatGPT „wszechwiedzącym, chętnym do pomocy stażystą, który czasem kłamie prosto w oczy”
W podobnym tonie wypowiada się Oren Etzioni, pionier w dziedzinie AI, który ostrzega, że system może dać „imponująco brzmiącą odpowiedź, która jest kompletnie błędna”
Z kolei polski ekspert Piotr Biczyk (QED Software) radzi, by nie traktować chatbota jak myślącej istoty, a jedynie narzędzie.
„Robią nie to, co byśmy chcieli, ale dokładnie to, do czego zostały przygotowane – próbują zgadnąć następne słowo w oparciu o dane, na których je nauczono”
– tłumaczy Biczyk
Podkreśla, że model nie ma intencji ani rozumienia, więc gdy pytanie jest nieprecyzyjne, AI tylko wypełnia lukę losowo najbardziej pasującym ciągiem słów – stąd biorą się niektóre błędy.
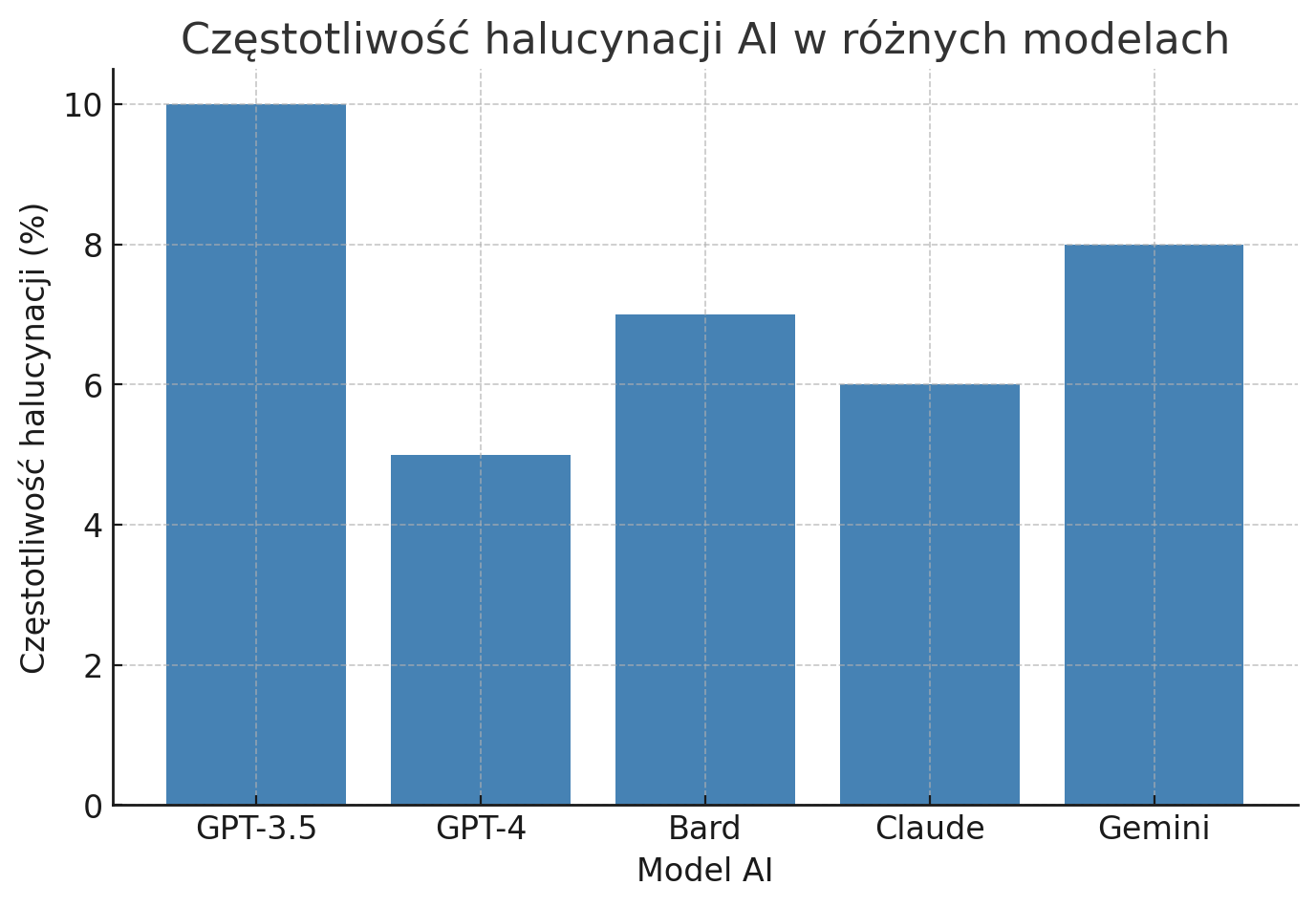
Eksperci zwracają też uwagę na skalę problemu. Według analiz, obecne modele potrafią halucynować w około 3–10% odpowiedzi.
Choć większość generowanych treści jest poprawna, to odsetek błędów jest na tyle duży, że przy szerokim zastosowaniu AI może powodować realne szkody. Jak ujął to Gary Marcus, znany krytyk AI, jeżeli chatboty mają być używane np. w medycynie czy prawie, nawet kilka procent błędnych odpowiedzi to zdecydowanie za dużo – trzeba dążyć do zminimalizowania tego odsetka, inaczej zaufanie publiczne zostanie podkopane.
Jak rozpoznać halucynacje AI?
Czy zwykły użytkownik może zorientować się, że dostał od AI halucynację, a nie prawdziwą odpowiedź? Choć bywa to trudne, istnieje kilka wskazówek, które mogą pomóc wychwycić błędne lub zmyślone informacje. Oto praktyczne rady:
1. Sprawdzaj źródła.
Jeśli chatbot podaje jakieś fakty, daty, cytaty – zapytaj go o źródło informacji. Coraz więcej modeli (w tym nowsze wersje ChatGPT) potrafi dostarczyć referencje. Brak źródła lub niemożność jego zweryfikowania powinna wzbudzić naszą czujność. Gdy AI przywołuje artykuł naukowy, warto sprawdzić, czy taki artykuł faktycznie istnieje (np. poprzez wyszukiwarkę lub bazę publikacji). Fikcyjne źródła to typowy objaw halucynacji.
2. Zwracaj uwagę na zbyt drobiazgowe szczegóły.
Halucynacje często są przesadnie konkretne. Jeśli model opisuje coś z wieloma detalami, których sami nie znamy – np. wymienia daty, nazwiska, liczby – i brzmi to zbyt pięknie, by było prawdziwe, warto to zweryfikować. AI potrafi zmyślać całe biografie czy anegdoty pełne szczegółów (jak historia Joyce’a i Lenina w Zurychu). Gdy coś brzmi nietypowo lub zaskakująco, lepiej założyć sceptycyzm.
3. Zadawaj dodatkowe pytania.
Jeśli podejrzewasz, że odpowiedź może być błędna, dopytaj AI o szczegóły lub sformułuj pytanie inaczej. Model nie zawsze powtarza halucynację w identyczny sposób. Możesz np. poprosić: “Czy jesteś pewien?”, “Skąd to wiesz?”. Czasem w odpowiedzi wyjdzie niepewność lub sprzeczność. Można też sprawdzić wiedzę modelu z innej perspektywy – zadać to samo pytanie innymi słowami lub zapytać o to samo inny model AI i porównać wyniki.
4. Weryfikuj z zewnętrznymi źródłami.
Najważniejsza zasada: nie ufaj ślepo, sprawdzaj samodzielnie. Jeśli ChatGPT podaje jakąś informację, spróbuj potwierdzić ją w Google, Wikipedii albo u eksperta z danej dziedziny. Szczególnie gdy chodzi o decyzje życiowe, porady medyczne, finansowe czy prawne – zawsze konsultuj to z człowiekiem lub oficjalnym źródłem. Traktuj odpowiedź AI jako wstępny szkic, a nie ostateczną prawdę objawioną.
5. Uważaj na swoje pytania.
Czasami to od pytania zależy, czy model zacznie halucynować. Bardzo ogólne, nieprecyzyjne polecenia dają AI duże pole do popisu (i do pomyłek). Staraj się więc formułować pytania jasno i konkretnie.
Dodaj kontekst, doprecyzuj, o co Ci chodzi. Jak radzą specjaliści, dobrze jest w promptach podawać konkretne instrukcje lub nawet przykład oczekiwanej odpowiedzi.
Im mniej niedopowiedzeń, tym mniejsza szansa, że model coś sobie dopowie.
6. Zachowaj zdrowy sceptycyzm.
Nawet jeśli odpowiedź wygląda profesjonalnie i spójnie, miej nawyk krytycznego myślenia. Czy ta informacja ma sens? Czy pasuje do tego, co już wiesz? Jeśli coś Ci intuicyjnie nie gra, lepiej to sprawdź. Trenuj się w dostrzeganiu ewentualnych niespójności – np. model najpierw podaje jedną liczbę, a potem inną, albo styl wypowiedzi nagle się zmienia. To mogą być sygnały, że odpowiedź nie jest w pełni wiarygodna.
Jak poprawić działanie AI?
Skoro halucynacje są tak istotnym problemem, co robią twórcy ChatGPT i innych modeli, by go ograniczyć? Okazuje się, że walka z konfabulacjami AI to dziś jedno z priorytetowych zadań w branży. Firmy i zespoły badawcze testują różne podejścia, aby uczynić modele bardziej wiarygodnymi.
Po pierwsze, ulepszane są metody treningu. OpenAI od początku stosuje tzw. uczenie ze wzmocnieniem z udziałem człowieka (RLHF) – ludzie oceniają odpowiedzi modelu i nagradzają go za poprawne, a karzą za błędne, co uczy model preferowanych zachowań. Jednak najnowsze pomysły idą dalej. W 2023 r. OpenAI zaproponowało nowy schemat szkolenia, w którym model otrzymuje nagrody nie tylko za poprawną końcową odpowiedź, ale też za poprawne pośrednie etapy rozumowania*
Innymi słowy, zamiast karać dopiero za końcowe „kłamstwo”, uczy się AI rozumować krok po kroku w kierunku prawdy. Takie nauczanie procesu myślenia – np. rozbijanie zadania na mniejsze części i weryfikowanie każdej z nich – ma zmniejszyć ryzyko, że pojedynczy błąd zaburzy cały wywód. Wstępne wyniki są obiecujące: OpenAI chwaliło się, że dzięki nagradzaniu prawidłowych etapów rozwiązywania zadania model znacznie lepiej radził sobie z trudnymi problemami (jak zadania matematyczne), jednocześnie popełniając mniej nonsensownych błędów
Choć badania te dotyczyły na razie wąskich zadań, wskazują kierunek, w jakim zmierzają prace – być może przyszłe AI będą lepiej „rozumować”, a mniej zgadywać.
Innym podejściem jest integrowanie modeli z zewnętrznymi bazami wiedzy i narzędziami. Microsoft wbudował model GPT-4 w wyszukiwarkę Bing, dzięki czemu chatbot może na bieżąco sprawdzać najnowsze informacje w sieci zamiast polegać wyłącznie na swojej pamięci.
Takie powiązanie z wyszukiwarką lub bazą danych może zapobiec typowym halucynacjom – jeśli model znajdzie konkretny fakt online, ma mniejszą pokusę, by go zmyślić.
Podobnie wtyczki i narzędzia dodawane do ChatGPT pozwalają mu np. wykonywać obliczenia w kalkulatorze czy sprawdzać fakty w Wikipedii na żądanie użytkownika. W ten sposób AI uczy się, że lepiej sprawdzić niż zmyślić. Pierwsze testy pokazują, że modele z dostępem do narzędzi generują mniej błędów merytorycznych, choć wciąż nie eliminują ich całkowicie.
Wiele uwagi poświęca się też wykrywaniu halucynacji przez same modele. Naukowcy z Uniwersytetu Oksfordzkiego zaprezentowali w 2023 r. metodę, która próbuje przewidzieć, kiedy model jest bliski halucynacji – analizując jego wewnętrzne stany i ocenę pewności odpowiedzi
Jeśli model sam „zrozumie”, że nie wie, istnieje szansa, że zamiast odpowiadać od razu, wycofa się lub zasygnalizuje użytkownikowi brak pewności. Innym pomysłem jest trenowanie AI do mówienia wprost „Nie znam odpowiedzi na to pytanie” w sytuacjach, gdy brakuje danych – taką postawę starano się wzmocnić w ChatGPT poprzez instrukcje i kary za konfabulacje.
Google przy tworzeniu własnego chatbota również postawiło na mechanizmy oceniające wiarygodność odpowiedzi i odrzucające te, które mogą być halucynacją. Jeden z dyrektorów Google przyznał, że ograniczenie halucynacji to zadanie fundamentalne przed pełnym wdrożeniem tych modeli do produktów dla masowego odbiorcy.
Trwają prace nad modelami hybrydowymi, które łączą w sobie podejście statystyczne z elementami logiki symbolicznej czy modułami weryfikującymi fakty.
Być może przyszłe AI będą wyposażone w wewnętrzne moduły “zdrowego rozsądku” albo będą potrafiły w tle sprawdzać sprzeczności w swojej odpowiedzi zanim ją wyślą użytkownikowi. Tego typu rozwiązania są na etapie badań, ale wiele wskazuje na to, że walka z halucynacjami będzie wymagała innowacyjnych zmian w samej architekturze modeli, a nie tylko doszlifowania obecnych metod.
Podsumowanie będzie krótkie…
….nie wolno bezkrytycznie ufać AI.
ChatGPT potrafi niesamowicie ułatwić życie, lecz bywa jak pewny siebie gawędziarz, który czasem doda od siebie koloryzowaną historię. To Twoją rolą (jako użytkownika) jest oddzielić fakty od fikcji.


Najbardziej obawiam się, że w przestrzeni informacyjnej przyjmie się to niezbyt szczęśliwe użycie terminu „halucynacje” w odniesieniu do AI. Niestety, to nie są „halucynacje”, a jedynie konfabulacja. A to zupełnie dwie, inne rzeczy.
Jeśli zaś chodzi o meritum sprawy, to nie rozumiem jednej – technicznie prostej rzeczy: dlaczego algorytm AI nie może po prostu odpowiedzieć „Nie wiem.”, „Nie mam danych na ten temat”, „Nie wiem, ale poszukam w sieci i przygotuję odpowiedź na podstawie konkretnych źródeł (i tu odpowiedź + lista odnośników do źródeł”. W czym jest problem, tak naprawdę? Ja jeśli czegoś nie wiem, po prostu mówię rozmówcy „Nie wiem tego”, jeśli rozmówca chce się czegoś jednak dowiedzieć, odpowiem „Nie wiem tego, ale mogę się dowiedzieć i wtedy odpowiem.”. To jest aż tak proste.